Здравствуйте, уважаемые читатели проекта Тюлягин! В сегодняшней статье про криптовалюты мы поговорим о хэше и хешировании. В статье вы узнаете что такое хэш и хэш-функция, узнаете как устроены хэши в целом и как работает хеширование в криптовалютах. Кроме этого приведены примеры хэша и даны ответы на наиболее популярные ответы о хэше и хешировании. Обо всем этом далее в статье.

Что такое хэш?
Хэш — это математическая функция, которая преобразует ввод произвольной длины в зашифрованный вывод фиксированной длины. Таким образом, независимо от исходного количества данных или размера файла, его уникальный хэш всегда будет одного и того же размера. Более того, хэши нельзя использовать для «обратного проектирования» входных данных из хешированных выходных данных, поскольку хэш-функции являются «односторонними» (как в мясорубке: вы не можете вернуть говяжий фарш обратно в стейк). Тем не менее, если вы используете такую функцию для одних и тех же данных, ее хэш будет идентичным, поэтому вы можете проверить, что данные такие же (т. е. без изменений), если вы уже знаете его хэш.
Хеширование также важно для управления блокчейном в криптовалюте.
Функция перестановок
Базовая функция перестановки состоит из раундов по пять шагов:
- Шаг
- Шаг
- Шаг
- Шаг
- Шаг
Тета, Ро, Пи, Хи, Йота
Далее будем использовать следующие обозначения:
Так как состояние имеет форму массива , то мы можем обозначить каждый бит состояния как
Обозначим результат преобразования состояния функцией перестановки
Также обозначим функцию, которая выполняет следующее соответствие:
— обычная функция трансляции, которая сопоставляет биту бит ,
где — длина слова (64 бит в нашем случае)
Я хочу вкратце описать каждый шаг функции перестановок, не вдаваясь в математические свойства каждого.
Шаг
Эффект отображения можно описать следующим образом: оно добавляет к каждому биту побитовую сумму двух столбцов и
Схематическое представление функции:
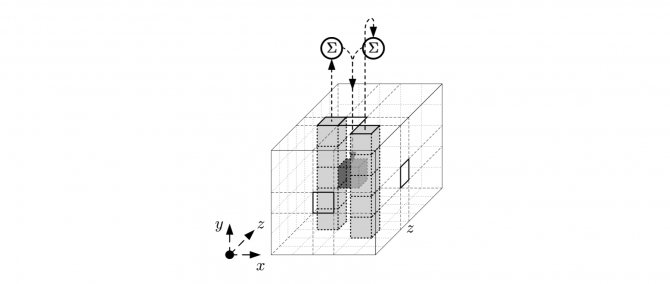
Псевдокод шага:

Шаг
Отображение направлено на трансляции внутри слов (вдоль оси z).
Проще всего его описать псевдокодом и схематическим рисунком:
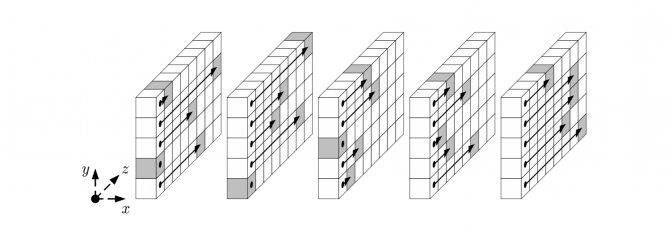
Шаг
Шаг представляется псевдокодом и схематическим рисунком:
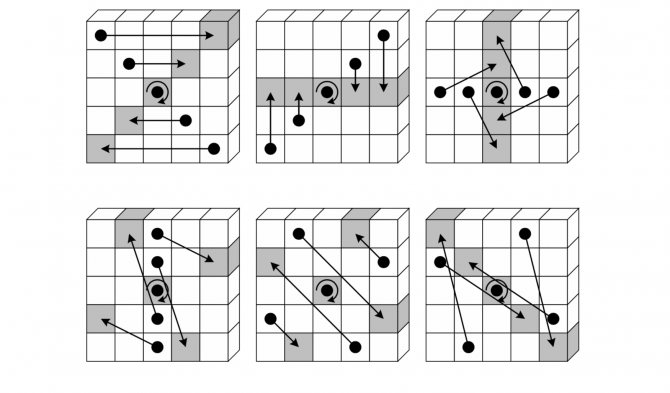
Шаг
Шаг является единственный нелинейным преобразованием в
Псевдокод и схематическое представление:
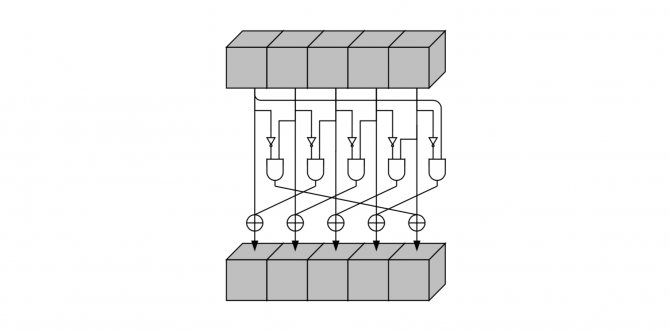
Шаг
Отображение состоит из сложения с раундовыми константами и направлено на нарушение симметрии. Без него все раунды были бы эквивалентными, что делало бы его подверженным атакам, использующим симметрию. По мере увеличения раундовые константы добавляют все больше и больше асимметрии.
Ниже приведена таблица раундовых констант для бит

Все шаги можно объединить вместе и тогда мы получим следующее:

Где константы являются циклическими сдвигами и задаются таблицей:

Как работают хэш-функции
Типичные хэш-функции принимают входные данные переменной длины для возврата выходных данных фиксированной длины. Криптографическая хэш-функция сочетает в себе возможности хэш-функций по передаче сообщений со свойствами безопасности.
Хэш-функции — это обычно используемые структуры данных в вычислительных системах для таких задач, как проверка целостности сообщений и аутентификация информации. Хотя они считаются криптографически «слабыми», поскольку могут быть решены за полиномиальное время, их нелегко расшифровать.
Криптографические хэш-функции добавляют функции безопасности к типичным хэш-функциям, что затрудняет обнаружение содержимого сообщения или информации о получателях и отправителях.
В частности, криптографические хэш-функции обладают этими тремя свойствами:
- Они «без коллизий». Это означает, что никакие два входных хэша не должны отображаться в один и тот же выходной хэш.
- Их можно скрыть. Должно быть трудно угадать входное значение для хэш-функции по ее выходным данным.
- Они должны быть паззл-ориентированными (быть головоломкой). Должно быть сложно подобрать вход, который обеспечивает предопределенный выход. Таким образом, входные данные следует выбирать из максимально широкого распределения.
Благодаря особенностям хэша они широко используются в онлайн-безопасности — от защиты паролей до обнаружения утечек данных и проверки целостности загруженного файла.
Свойства
Криптографическая хеш-функция должна уметь противостоять всем известным типам криптоаналитических атак. В теоретической криптографии уровень безопасности хеш-функции определяется с использованием следующих свойств:
Pre-image resistance
Имея заданное значение h, должно быть сложно найти любое сообщение m такое, что
Second pre-image resistance
Имея заданное входное значение , должно быть сложно найти другое входное значение такое, что
Collision resistance
Должно быть сложно найти два различных сообщения и таких, что
Такая пара сообщений и называется коллизией хеш-функции
Давайте чуть более подробно поговорим о каждом из перечисленных свойств.
Collision resistance. Как уже упоминалось ранее, коллизия происходит, когда разные входные данные производят одинаковый хеш. Таким образом, хеш-функция считается устойчивой к коллизиям до того момента, пока не будет обнаружена пара сообщений, дающая одинаковый выход. Стоит отметить, что коллизии всегда будут существовать для любой хеш-функции по той причине, что возможные входы бесконечны, а количество выходов конечно. Хеш-функция считается устойчивой к коллизиям, когда вероятность обнаружения коллизии настолько мала, что для этого потребуются миллионы лет вычислений.
Несмотря на то, что хеш-функций без коллизий не существует, некоторые из них достаточно надежны и считаются устойчивыми к коллизиям.
Pre-image resistance. Это свойство называют сопротивлением прообразу. Хеш-функция считается защищенной от нахождения прообраза, если существует очень низкая вероятность того, что злоумышленник найдет сообщение, которое сгенерировало заданный хеш. Это свойство является важным для защиты данных, поскольку хеш сообщения может доказать его подлинность без необходимости раскрытия информации. Далее будет приведён простой пример и вы поймете смысл предыдущего предложения.
Second pre-image resistance. Это свойство называют сопротивлением второму прообразу. Для упрощения можно сказать, что это свойство находится где-то посередине между двумя предыдущими. Атака по нахождению второго прообраза происходит, когда злоумышленник находит определенный вход, который генерирует тот же хеш, что и другой вход, который ему уже известен. Другими словами, злоумышленник, зная, что пытается найти такое, что
Отсюда становится ясно, что атака по нахождению второго прообраза включает в себя поиск коллизии. Поэтому любая хеш-функция, устойчивая к коллизиям, также устойчива к атакам по поиску второго прообраза.
Неформально все эти свойства означают, что злоумышленник не сможет заменить или изменить входные данные, не меняя их хеша.
Таким образом, если два сообщения имеют одинаковый хеш, то можно быть уверенным, что они одинаковые.
В частности, хеш-функция должна вести себя как можно более похоже на случайную функцию, оставаясь при этом детерминированной и эффективно вычислимой.

Хеширование и криптовалюты
Основой криптовалюты является блокчейн, который представляет собой глобальный распределенный реестр, образованный путем связывания отдельных блоков данных транзакции. Блокчейн содержит только подтвержденные транзакции, что предотвращает мошеннические транзакции и двойное расходование валюты. Полученное зашифрованное значение представляет собой серию цифр и букв, не похожих на исходные данные, и называется хэшем. Майнинг криптовалюты предполагает работу с этим хэшем.
Хеширование требует обработки данных из блока с помощью математической функции, что приводит к выходу фиксированной длины. Использование вывода фиксированной длины повышает безопасность, поскольку любой, кто пытается расшифровать хэш, не сможет определить, насколько длинным или коротким является ввод, просто посмотрев на длину вывода.
Решение хэша начинается с данных, имеющихся в заголовке блока, и, по сути, решает сложную математическую задачу. Заголовок каждого блока содержит номер версии, метку времени, хэш, использованный в предыдущем блоке, хэш корня Меркла, одноразовый номер (nonce) и целевой хэш.
Майнер сосредотачивается на nonce, строке чисел. Этот номер добавляется к хешированному содержимому предыдущего блока, которое затем хешируется. Если этот новый хэш меньше или равен целевому хэшу, то он принимается в качестве решения, майнеру дается вознаграждение, и блок добавляется в цепочку блоков.
Процесс проверки транзакций блокчейна основан на шифровании данных с использованием алгоритмического хеширования.
Keccak
Хеш-функции семейства Keccak построены на основе конструкции криптографической губки, в которой данные сначала «впитываются» в губку, а затем результат Z «отжимается» из губки.
Любая губчатая функция Keccak использует одну из семи перестановок которая обозначается , где
перестановки представляют собой итерационные конструкции, состоящие из последовательности почти одинаковых раундов. Число раундов зависит от ширины перестановки и задаётся как где
В качестве стандарта SHA-3 была выбрана перестановка Keccak-f[1600], для неё количество раундов
Далее будем рассматривать
Давайте сразу введем понятие строки состояния, которая играет важную роль в алгоритме.
Строка состояния представляет собой строку длины 1600 бит, которая делится на и части, которые называются скоростью и ёмкостью состояния соотвественно.
Соотношение деления зависит от конкретного алгоритма семейства, например, для SHA3-256
В SHA-3 строка состояния S представлена в виде массива слов длины бит, всего бит. В Keccak также могут использоваться слова длины , равные меньшим степеням 2.
Алгоритм получения хеш-функции можно разделить на несколько этапов:
• С помощью функции дополнения исходное сообщение M дополняется до строки P длины кратной r
• Строка P делится на n блоков длины
• «Впитывание»: каждый блок дополняется нулями до строки длиной бит (b = r+c) и суммируется по модулю 2 со строкой состояния , далее результат суммирования подаётся в функцию перестановки и получается новая строка состояния , которая опять суммируется по модулю 2 с блоком и дальше опять подаётся в функцию перестановки . Перед началом работы криптографической губки все элементыравны 0.
• «Отжимание»: пока длина результата меньше чем , где — количество бит в выходном массиве хеш-функции, первых бит строки состояния добавляется к результату . После каждой такой операции к строке состояния применяется функция перестановок и данные продолжают «отжиматься» дальше, пока не будет достигнуто значение длины выходных данных .
Все сразу станет понятно, когда вы посмотрите на картинку ниже:
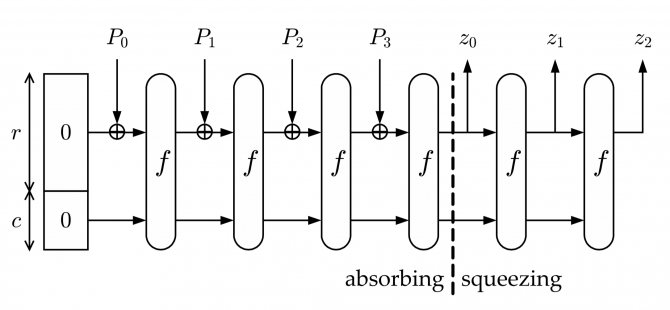
Функция дополнения
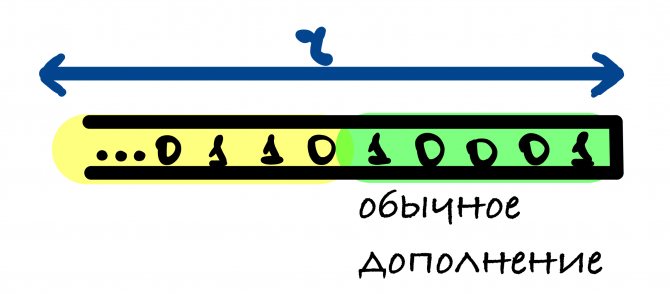
В SHA-3 используется следующий шаблон дополнения 10…1: к сообщению добавляется 1, после него от 0 до r — 1 нулевых бит и в конце добавляется 1.
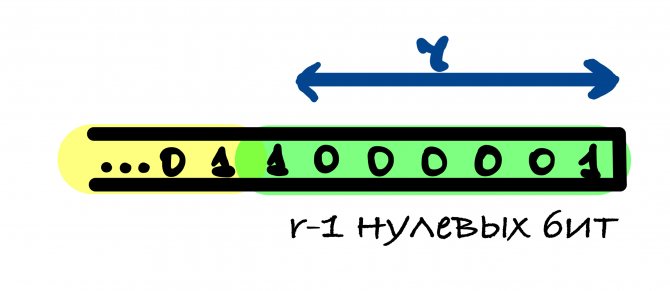
r — 1 нулевых бит может быть добавлено, когда последний блок сообщения имеет длину r — 1 бит. В этом случае последний блок дополняется единицей и к нему добавляется блок, состоящий из r — 1 нулевых бит и единицы в конце.
Если длина исходного сообщения M делится на r, то в этом случае к сообщению добавляется блок, начинающийся и оканчивающийся единицами, между которыми находятся r — 2 нулевых бит. Это делается для того, чтобы для сообщения, оканчивающегося последовательностью бит как в функции дополнения, и для сообщения без этих бит значения хеш-функции были различны.
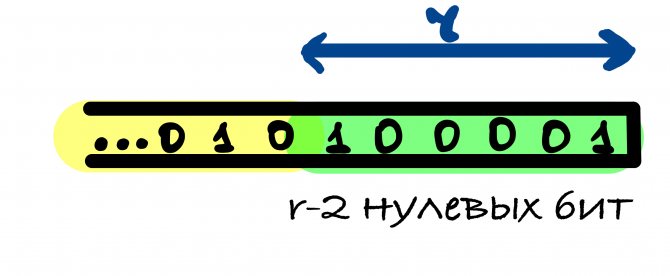
Первый единичный бит в функции дополнения нужен, чтобы результаты хеш-функции от сообщений, отличающихся несколькими нулевыми битами в конце, были различны.
Особенности хэша
Решение хэша требует, чтобы майнер определил, какую строку использовать в качестве одноразового номера, что само по себе требует значительного количества проб и ошибок. Это потому, что одноразовый номер — это случайная строка. Маловероятно, что майнер успешно найдет правильный одноразовый номер с первой попытки, а это означает, что майнер потенциально может протестировать большое количество вариантов одноразового номера, прежде чем сделать его правильным. Чем выше сложность — мера того, насколько сложно создать хэш, который удовлетворяет требованиям целевого хэша — тем больше времени, вероятно, потребуется для генерации решения.
SHA1, SHA2, SHA3
Secure Hashing Algorithm (SHA1) — алгоритм, созданный Агентством национальной безопасности (NSA). Он создает 160-битные выходные данные фиксированной длины. На деле SHA1 лишь улучшил MD5 и увеличил длину вывода, а также увеличил число однонаправленных операций и их сложность. Однако каких-нибудь фундаментальных улучшений не произошло, особенно когда разговор шел о противодействии более мощным вычислительным машинам. Со временем появилась альтернатива — SHA2, а потом и SHA3. Последний алгоритм уже принципиально отличается по архитектуре и является частью большой схемы алгоритмов хеширования (известен как KECCAK — «Кетч-Ак»). Несмотря на схожесть названия, SHA3 имеет другой внутренний механизм, в котором используются случайные перестановки при обработке данных — «Впитывание» и «Выжимание» (конструкция «губки»).
Пример хэша и хеширования
Хеширование слова «привет» даст результат той же длины, что и хэш для «Я иду в магазин». Функция, используемая для генерации хэша, является детерминированной, что означает, что она будет давать один и тот же результат каждый раз, когда используется один и тот же ввод. Он может эффективно генерировать хешированный ввод, это также затрудняет определение ввода (что приводит к майнингу), а также вносит небольшие изменения в результат ввода в неузнаваемый, совершенно другой хэш.
Обработка хэш-функций, необходимых для шифрования новых блоков, требует значительной вычислительной мощности компьютера, что может быть дорогостоящим. Чтобы побудить людей и компании, называемые майнерами, инвестировать в необходимую технологию, сети криптовалюты вознаграждают их как новыми токенами криптовалюты, так и комиссией за транзакцию. Майнеры получают вознаграждение только в том случае, если они первыми создают хэш, который соответствует требованиям, изложенным в целевом хэш-коде.
Как при помощи хеша ловить вирусы?
Примерно так же, как звукозаписывающие лейблы и кинопрокатные компании защищают свой контент, сообщество создает списки зловредов (многие из них доступны публично), а точнее, списки их хешей. Причем это может быть хеш не всего зловреда целиком, а лишь какого-либо его специфического и хорошо узнаваемого компонента. С одной стороны, это позволяет пользователю, обнаружившему подозрительный файл, тут же внести его хеш-код в одну из подобных открытых баз данных и проверить, не является ли файл вредоносным. С другой — то же самое может сделать и антивирусная программа, чей «движок» использует данный метод детектирования наряду с другими, более сложными.
Криптографические хеш-функции также могут использоваться для защиты от фальсификации передаваемой информации. Иными словами, вы можете удостовериться в том, что файл по пути куда-либо не претерпел никаких изменений, сравнив его хеши, снятые непосредственно до отправки и сразу после получения. Если данные были изменены даже всего на 1 байт, хеш-коды будут отличаться, как мы уже убедились в самом начале статьи. Недостаток такого подхода лишь в том, что криптографическое хеширование требует больше вычислительных мощностей или времени на вычисление, чем алгоритмы с отсутствием криптостойкости. Зато они в разы надежнее.
Кстати, в повседневной жизни мы, сами того не подозревая, иногда пользуемся простейшими хешами. Например, представьте, что вы совершаете переезд и упаковали все вещи по коробкам и ящикам. Погрузив их в грузовик, вы фиксируете количество багажных мест (то есть, по сути, количество коробок) и запоминаете это значение. По окончании выгрузки на новом месте, вместо того чтобы проверять наличие каждой коробки по списку, достаточно будет просто пересчитать их и сравнить получившееся значение с тем, что вы запомнили раньше. Если значения совпали, значит, ни одна коробка не потерялась.
Популярные вопросы о хэше
Что такое хэш и хэш-функция?
Хэш-функции — это математические функции, которые преобразуют или «отображают» заданный набор данных в битовую строку фиксированного размера, также известную как «хэш» (хэш кодом, хэш суммой, значением хэша и т.д.).
Как рассчитывается хэш?
Хэш-функция использует сложные математические алгоритмы, которые преобразуют данные произвольной длины в данные фиксированной длины (например, 256 символов). Если вы измените один бит в любом месте исходных данных, изменится все значение хэш-функции, что сделает его полезным для проверки точности цифровых файлов и других данных.
Для чего используются хэши в блокчейнах?
Хэши используются в нескольких частях блокчейн-системы. Во-первых, каждый блок содержит хэш заголовка блока предыдущего блока, гарантируя, что ничего не было изменено при добавлении новых блоков. Майнинг криптовалюты с использованием доказательства выполнения работы (PoW), кроме того, использует хеширование случайно сгенерированных чисел для достижения определенного хешированного значения, содержащего серию нулей в начале. Эта произвольная функция требует больших ресурсов, что затрудняет перехват сети злоумышленником.
Стандарты хеширования: популярные варианты
Итак, от экскурса в историю перейдем вновь к серьезной теме. Опять-таки, ради простоты восприятия предлагаем краткое описание популярных стандартов хеширования в табличном виде. Так проще оценить информацию и провести сравнение.
| Название | Краткий обзор |
| CRC-32 | Полином CRC (Cyclic Redundancy Check, что значит «циклическая проверка излишков»). Является мощным легко осуществимым методом хеширования для достижения надежности информации. Применяется для защиты данных и обнаружении ошибок в потоке информации. Популярность принесли следующие качества: высочайшая степень обнаружения ошибок, минимальные расходы, простота эксплуатирования. Генерирует 32-битный хэш. Используется комитетом по стандартам локальных систем. |
| MD5 | Протокол базируется на 128-битном (16-байтном) фундаменте. Применяется для хранения паролей, создания уникальных криптографических ключей и ЭЦП. Используется для аудита подлинности и целостности документов в ПК. Недостаток – сравнительно легкое нахождение коллизий. |
| SHA-1 | Реализует хеширование и шифрование по принципу сжатия. Входы такого алгоритма сжатия состоят из набора данных длиной 512 Бит и выходом предыдущего блока. Количество раундов – 80. Размер значения хэш – 32 Бит. Найденные коллизии – 252 операции. Рекомендовано для основного использования в госструктурах США. |
| SHA-2 | Семейство протоколов – однонаправленных криптографических алгоритмов, куда входит легендарный SHA-256, используемый в Bitcoin. Размер блока – 512/1024 Бит. Количество раундов 64/80. Найденных коллизий не существует. Размер значения однонаправленных хэш-функций – 32 Бит. |
| ГОСТ Р 34.11-2012 «Стрибог» | Детище отечественных программистов, состоящее из пары хэш-функций, с длинами итогового значения 256 и 512 Бит, отличающиеся начальным состоянием и результатом вычисления. Криптографическая стойкость – 2128. Преобразование массива данных основано на S-блоках, что существенно осложняет поиск коллизий. |
На этом, пожалуй, закончим экскурсию в мир сложных, но весьма полезных и востребованных протоколов хеширования.
Вам также может быть интересно .

Криптография 0
Резюме
- Хэш — это функция, которая удовлетворяет требования к шифрованию, необходимые для решения вычислений в цепочке блоков.
- Хэши имеют фиксированную длину, так как практически невозможно угадать длину хэша, если кто-то пытался взломать блокчейн.
- Одни и те же данные всегда будут давать одно и то же хешированное значение.
- Хэш, как одноразовый номер или решение, является основой сети блокчейн.
- Хэш создается на основе информации, содержащейся в заголовке блока.
А на этом сегодня все про хэш и хеширование. Надеюсь статья оказалась для вас полезной. Делитесь статьей в социальных сетях и мессенджерах и добавляйте сайт в закладки. Успехов и до новых встреч на страницах проекта Тюлягин!
- 1
Поделиться
Алгоритм MD5 и его подверженность взлому
MD5 hash — один из первых стандартов алгоритма, который применялся в целях проверки целостности файлов (контрольных сумм). Также с его помощью хранили пароли в базах данных web-приложений. Функциональность относительно проста — алгоритм выводит для каждого ввода данных фиксированную 128-битную строку, задействуя для вычисления детерминированного результата однонаправленные тривиальные операции в нескольких раундах. Особенность — простота операций и короткая выходная длина, в результате чего MD5 является относительно легким для взлома. А еще он обладает низкой степенью защиты к атаке типа «дня рождения».
Атака дня рождения
Если поместить 23 человека в одну комнату, можно дать 50%-ную вероятность того, что у двух человек день рождения будет в один и тот же день. Если же количество людей довести до 70-ти, вероятность совпадения по дню рождения приблизится к 99,9 %. Есть и другая интерпретация: если голубям дать возможность сесть в коробки, при условии, что число коробок меньше числа голубей, окажется, что хотя бы в одной из коробок находится более одного голубя.

Вывод прост: если есть фиксированные ограничения на выход, значит, есть и фиксированная степень перестановок, на которых существует возможность обнаружить коллизию.
Когда разговор идет о сопротивлении коллизиям, то алгоритм MD5 действительно очень слаб. Настолько слаб, что даже бытовой Pentium 2,4 ГГц сможет вычислить искусственные хеш-коллизии, затратив на это чуть более нескольких секунд. Всё это в ранние годы стало причиной утечки большого количества предварительных MD5-прообразов.
Улучшение хэш-кода () Реализация
Давайте немного улучшить текущее хэш-код ()
реализации путем включения всех областей
Пользователь
класс, чтобы он может дать различные результаты для неравных объектов:
@Override public int hashCode() { return (int) id * name.hashCode() * email.hashCode(); }
Этот базовый алгоритм хэширования определенно намного лучше предыдущего, так как он вычисляет хэш-код объекта, просто умножая хэш-коды имя
и
электронной
полей и
id
.
В общих чертах можно сказать, что это разумный хэш-код ()
реализации, до тех пор, как мы
равны ()
реализации в соответствии с ним.
Обработка устаревших хэшей SHA-1
Все крупные поставщики веб-браузеров (например, Microsoft, Google, Mozilla, Apple) и другие доверенные стороны рекомендовали всем клиентам, сервисам и продуктам, в настоящее время использующим SHA-1, перейти на SHA-2, хотя что и когда должно перейти зависит от поставщика. Например, многие поставщики заботятся только о сертификатах TLS (т. е. веб-серверах), и только компания Microsoft озабочена использованием SHA-1 в цифровом сертификате от «публичного» центра сертификации. Но можно ожидать, что все поставщики потребуют перевести на SHA-2 все приложения и устройства, даже если они не готовы к этому. Сейчас большинство браузеров покажет сообщение об ошибке, если на веб-сайте используется публичный цифровой сертификат, подписанный SHA-1, но некоторые из них позволят вам обойти всплывающее окно и перейти на такой сайт. Возможно, в скором времени, все главные поставщики браузеров запретят обход сообщений об ошибке и переходы на сайты, использующие цифровые сертификаты SHA-1.
К сожалению, переход с SHA-1 на SHA-2 является односторонней операцией в большинстве сценариев сервера. Например, как только вы начнёте использовать цифровой сертификат SHA-2 вместо SHA-1, пользователи, не понимающие сертификаты SHA-2, начнут получать предупреждения и уведомления об ошибках, или даже отказы. Для пользователей приложений и устройств, не поддерживающих SHA-2, переход будет опасным скачком.
Наивный хэш-код () Реализация
Это на самом деле довольно просто иметь наивный хэш-код ()
полностью придерживается вышеупомянутого контракта.
Чтобы продемонстрировать это, мы собираемся определить образец Пользователь
класс, переопределяет реализацию метода по умолчанию:
public class User { private long id; private String name; private String email; // standard getters/setters/constructors @Override public int hashCode() { return 1; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == NULL) return false; if (this.getClass() != o.getClass()) return false; User user = (User) o; return id == user.id && (name.equals(user.name) && email.equals(user.email)); } // getters and setters here }
Пользователь
класс предоставляет пользовательские реализации для обеих равны () и хэш-код () которые полностью придерживаются соответствующих контрактов. Более того, нет ничего незаконного в том, чтобы
хэш-код ()
возврат любого фиксированного значения.
Однако эта реализация ухудшает функциональность хэш-таблиц практически до нуля, так как каждый объект будет храниться в одном и том же ведре.
В этом контексте поиск хэш-таблицы выполняется линейно и не дает нам реального преимущества – подробнее об этом в разделе 7.
Стандартный хэш-код () Реализации
Чем лучше алгоритм хэширования, который мы используем для вычисления хэш-кодов, тем лучше будет производительность хэш-таблиц.
Давайте посмотрим на “стандартную” реализацию, которая использует два основных числа, чтобы добавить еще больше уникальности в вычисленные хэш-коды:
@Override public int hashCode() { int hash = 7; hash = 31 * hash + (int) id; hash = 31 * hash + (name == NULL ? 0 : name.hashCode()); hash = 31 * hash + (email == NULL ? 0 : email.hashCode()); return hash; }
Хотя очень важно понимать роли, которые хэш-код ()
и
равны ()
методы игры, мы не должны осуществлять их с нуля каждый раз, так как большинство IDEs может генерировать пользовательские
хэш-код ()
и
равны ()
реализации и с Java 7, мы получили Объекты.хэш () утилита для удобного хэширования:
Objects.hash(name, email)
IntelliJ IDEA генерирует следующую реализацию:
@Override public int hashCode() { int result = (int) (id ^ (id >>> 32)); result = 31 * result + name.hashCode(); result = 31 * result + email.hashCode(); return result; }
И Затмение производит этот:
@Override public int hashCode() { final int prime = 31; int result = 1; result = prime * result + ((email == NULL) ? 0 : email.hashCode()); result = prime * result + (int) (id ^ (id >>> 32)); result = prime * result + ((name == NULL) ? 0 : name.hashCode()); return result; }
В дополнение к вышеупомянутому IDE- хэш-код ()
реализаций, это также возможно автоматически генерировать эффективную реализацию, например, с помощью Ломбок . В этом случае ломбок-мавен зависимость должна быть добавлена к пом.xml :
org.projectlomboklombok-maven1.16.18.0pom
Теперь достаточно аннотировать Пользователь
класс с
@EqualsAndHashCode
:
@EqualsAndHashCode public class User { // fields and methods here }
Точно так же, если мы хотим Апач Викисклад Ланг HashCodeBuilder
класс для создания
хэш-код ()
реализации для нас, общий ланг Зависимость Maven должна быть включена в файл pom:
commons-langcommons-lang2.6
И хэш-код ()
могут быть реализованы так:
public class User { public int hashCode() { return new HashCodeBuilder(17, 37). append(id). append(name). append(email). toHashCode(); } }
В общем, нет универсального рецепта придерживаться, когда дело доходит до реализации хэш-код ()
. Мы настоятельно рекомендуем читать Эффективный Java- Джошуа , который предоставляет список тщательные руководящие принципы
Что можно заметить здесь, что все эти реализации использовать номер 31 в той или иной форме – это потому, что 31 имеет хорошее свойство – его умножение может быть заменено немного сдвиг, который быстрее, чем стандартное умножение:
31 * i == (i << 5) — i
Использование хэш-кода () в структурах данных
Простейшие операции по сборам могут быть неэффективными в определенных ситуациях.
Например, это вызывает линейный поиск, который является крайне неэффективным для списков огромных размеров:
List words = Arrays.asList(«Welcome», «to», «Baeldung»); if (words.contains(«Baeldung»)) { System.out.println(«Baeldung is in the list»); }
Java предоставляет ряд структур данных для решения этой проблемы в частности – например, несколько Карта
реализации интерфейса хэш-таблицы.
При использовании хэш-стола эти коллекции вычисляют значение хэша для данного ключа с помощью хэш-код ()
метод и использовать это значение внутренне для хранения данных, чтобы операции доступа были гораздо более эффективными.
План перехода ИОК с SHA-1 на SHA-2
Каждая компания с внутренним ИОК, не использующая SHA-2, должна будет создать ИОК SHA-2 или перевести существующую ИОК с SHA-1 на SHA-2. Для перехода нужно:
- Обучить вовлечённых членов команды тому, что такое SHA-2 и почему требуется его использование (эта статья будет хорошим началом).
- Провести инвентаризацию всех критических хешей или цифровых сертификатов, используемых в приложениях или устройствах.
- Определить, какие критически важные устройства или приложения могут использовать SHA-2, какой размер ключа может быть использован и какие операционные проблемы могут возникнуть (этот этап зачастую включает обращение к поставщику и тестирование).
- Определить, какие компоненты ИОК могут или должны быть перенесены в SHA-2.
- Составить план перехода для преобразования компонентов SHA-1 в SHA-2, включая потребителей и компоненты ИОК, плюс резервный план на случай сбоя.
- Провести PoC-тестирование.
- Принять управленческий риск и решение о переходе или отказе от него.
- Внедрить план перехода в производственную среду.
- Провести тестирование и получить обратную связь.
Самая сложная часть перехода — определение того, какие устройства и приложения работают с SHA-2. Если используемые устройства не понимают SHA-2, вас ждёт неудача или сообщение об ошибке, которое вряд ли будет звучать как «SHA-2 не принят». Вместо этого готовьтесь к: «Сертификат не распознан», «Соединение нестабильно», «Соединение не может быть установлено», «Повреждённый сертификат» или «Непроверенный сертификат».
Подумайте о своей миссии, чтобы определить, какие важные части вашей инфраструктуры будут или не будут работать. Начните с попытки инвентаризации каждого уникального устройства, ОС и приложения, которые должны понимать SHA-2. Затем соберите команду людей, которые протестируют, работает ли SHA-2. Можно предварительно полагаться на информацию от поставщиков, но вы не будете знать наверняка пока не проверите самостоятельно.
Обновление приложений и устройств — задача не из лёгких, и потребует больше времени, чем кажется. Даже сейчас существует множество устройств и приложений, использующих старые версии OpenSSL, которые следовало бы обновить после атаки Heartbleed, но администраторы серверов этого так и не сделали.
Если у вас есть внутренняя ИОК, вам понадобится подготовить её к переходу на SHA-2. Иногда это означает обновление ваших центров сертификации, получение новых сертификатов или установку полностью новых ИОК. Последнее рекомендуется по множеству причин, в основном потому, что новая ИОК даст вам шанс начать сначала без груза старых ошибок.