Если постараться дать определение простыми словами, что такое big data (биг дата или в переводе большой объем данных), то это обобщающее название для информационного потока, технологии, методов его обработки и системы анализа. Он обрабатывается путем применения программных инструментов, ставших аналогом традиционным базам и решениям Business Intelligence. Все действия направлены на структурирование и получение новых выводов.
Что это такое
IT-сфера уверенно заполняет пространство вокруг людей. Однако получаемые знания не могут уходить «вникуда», а учитывая колоссальный размер, хранилище должно быть объемным. Человечество уже давно перешло на цифровые носители, при этом все они отличаются по размеру.
Для работы с большими массивами информации нужен специальный набор инструментов и методик, чтобы с их помощью решать конкретные поставленные задачи. По сути, совокупность различных данных и инструментарий работы с ними и определяет термин Big Data.
Этот социально-экономический феномен напрямую связан с появлением масштабируемых технологий, которые позволяют работать с огромным количеством информации.
Принципы работы с большими данными
Исходя из определения Big Data
, можно сформулировать основные принципы работы с такими данными:
1. Горизонтальная масштабируемость
. Поскольку данных может быть сколь угодно много – любая система, которая подразумевает обработку больших данных, должна быть расширяемой. В 2 раза вырос объём данных – в 2 раза увеличили количество железа в кластере и всё продолжило работать.
2. Отказоустойчивость
. Принцип горизонтальной масштабируемости подразумевает, что машин в кластере может быть много. Например, Hadoop-кластер Yahoo имеет более 42000 машин (по этой ссылке можно посмотреть размеры кластера в разных организациях). Это означает, что часть этих машин будет гарантированно выходить из строя. Методы работы с большими данными должны учитывать возможность таких сбоев и переживать их без каких-либо значимых последствий.
3. Локальность данных.
В больших распределённых системах данные распределены по большому количеству машин. Если данные физически находятся на одном сервере, а обрабатываются на другом – расходы на передачу данных могут превысить расходы на саму обработку. Поэтому одним из важнейших принципов проектирования BigData-решений является принцип локальности данных – по возможности обрабатываем данные на той же машине, на которой их храним.
Все современные средства работы с большими данными так или иначе следуют этим трём принципам. Для того, чтобы им следовать – необходимо придумывать какие-то методы, способы и парадигмы разработки средств разработки данных. Один из самых классических методов я разберу в сегодняшней статье.
Разница используемых методик
Всего выделяют 2 основных подхода к аналитике, которые имеют кардинально разные стратегии.
| Традиционная | Современная |
| Анализирование небольших инфо-блоков | Обработка всего массива информации сразу |
| Редактирование, структурирование | Использование исходников |
| Разработка и проверка гипотез | Поиск соотношений по всему потоку до достижения результата |
| Поэтапность: сбор, хранение, анализ | Аналитика в реальном времени |
Как работают с большими данными
Когда данные получены и сохранены, их нужно проанализировать и представить в понятном для клиента виде: графики, таблицы, изображения или готовые алгоритмы. Из-за объема и сложности в обработке традиционные способы не подходят. С большими данными необходимо:
- обрабатывать весь массив данных (а это Петабайты);
- искать корреляции по всему массиву (в том числе скрытые);
- обрабатывать и анализировать информацию в реальном времени.
Поэтому для работы с big data разработаны отдельные технологии.
Технологии
Изначально это средства обработки неопределенно структурированных данных: СУБД NoSQL, алгоритмы MapReduce, Hadoop.
MapReduce — фреймворк для параллельных вычислений очень больших наборов данных (до нескольких Петабайт). Разработан Google (2004 год).
NoSQL (от англ. Not Only SQL, не только SQL). Помогает работать с разрозненными данными, решает проблемы масштабируемости и доступности с помощью атомарности и согласованности данных.
Hadoop — проект фонда Apache Software Foundation. Это набор утилит, библиотек и фреймворков, который служит для разработки и выполнения распределенных программ, работающих на кластерах из сотен и тысяч узлов. О нём уже говорили, но это потому, что без Hadoop не обходится практически ни один проект связанный с большими данными.
Также к технологиям относят языки программирования R и Python, продукты Apache.
Методы и средства работы с большими данными
Это дата майнинг, машинное обучение, краудсорсинг, прогнозная аналитика, визуализация, имитационное моделирование. Методик десятки:
- смешение и интеграция разнородных данных, например, цифровая обработка сигналов;
- прогнозная аналитика — использует данные за прошлые периоды и прогнозирует события в будущем;
- имитационное моделирование — строит модели, которые описывают процессы, как если бы они происходили в действительности;
- пространственный и статистический анализ;
- визуализация аналитических данных: рисунки, графики, диаграммы, таблицы.
Например, machine learning — это метод ИИ, который учит компьютер самостоятельно «думать», анализировать информацию и принимать решения после обучения, а не по запрограммированной человеком команде.
Алгоритмам обучения нужны структурированные данные, на основе которых компьютер будет учиться. Например, если играть с машиной в шашки и выигрывать, то машина запоминает только правильные ходы, но не анализирует процесс игры. Если оставить компьютер играть с самим собой, то он поймет ход игры, разработает стратегию, и живой человек начнет проигрывать машине. В этом случае она не просто делает ходы, а «думает».
Deep learning – отдельный вид machine learning, в ходе которого создаются новые программы, способные самостоятельно обучаться. И здесь используются искусственные нейронные сети, которые имитируют нейронные сети человека. Компьютеры обрабатывают неструктурированные данные, анализируют, делают выводы, иногда совершают ошибки и учатся — почти, как люди.
Результат deep learning применяют в обработке изображений, алгоритмах распознавания речи, компьютерных переводах и других технологиях. Картины, нарисованные нейросетями Яндекса, и остроумные ответы Алисы на ваши вопросы — результат deep learning.
Data Engineer
Это уже «человеческая» часть работы с большими данными. Data Engineer или инженер данных — это специалист по обработке данных. Он готовит инфраструктуру для работы и данные для Data Scientist:
- разрабатывает, тестирует и поддерживает базы данных, хранилища и системы массовой обработки;
- очищает и подготавливает данные для использования — создает пайплайн обработки данных.
После Data Engineer в дело вступает Data Scientist: создает и обучает предиктивные (и не только) модели с помощью алгоритмов машинного обучения и нейросетей, помогая бизнесу находить скрытые закономерности, прогнозировать развитие событий и оптимизировать бизнес-процессы.
Готовые решения для всех направлений
Магазины
Мобильность, точность и скорость пересчёта товара в торговом зале и на складе, позволят вам не потерять дни продаж во время проведения инвентаризации и при приёмке товара.
Узнать больше
Склады
Ускорь работу сотрудников склада при помощи мобильной автоматизации. Навсегда устраните ошибки при приёмке, отгрузке, инвентаризации и перемещении товара.
Узнать больше
Маркировка
Обязательная маркировка товаров — это возможность для каждой организации на 100% исключить приёмку на свой склад контрафактного товара и отследить цепочку поставок от производителя.
Узнать больше
E-commerce
Скорость, точность приёмки и отгрузки товаров на складе — краеугольный камень в E-commerce бизнесе. Начни использовать современные, более эффективные мобильные инструменты.
Узнать больше
Учреждения
Повысь точность учета имущества организации, уровень контроля сохранности и перемещения каждой единицы. Мобильный учет снизит вероятность краж и естественных потерь.
Узнать больше
Производство
Повысь эффективность деятельности производственного предприятия за счет внедрения мобильной автоматизации для учёта товарно-материальных ценностей.
Узнать больше
RFID
Первое в России готовое решение для учёта товара по RFID-меткам на каждом из этапов цепочки поставок.
Узнать больше
ЕГАИС
Исключи ошибки сопоставления и считывания акцизных марок алкогольной продукции при помощи мобильных инструментов учёта.
Узнать больше
Сертификация для партнеров
Получение сертифицированного статуса партнёра «Клеверенс» позволит вашей компании выйти на новый уровень решения задач на предприятиях ваших клиентов..
Узнать больше
Инвентаризация
Используй современные мобильные инструменты для проведения инвентаризации товара. Повысь скорость и точность бизнес-процесса.
Узнать больше
Мобильная автоматизация
Используй современные мобильные инструменты в учете товара и основных средств на вашем предприятии. Полностью откажитесь от учета «на бумаге».
Узнать больше Показать все решения по автоматизации
Технологии больших данных
Наконец, мы рассмотрим основные инструменты, которые используют современные специалисты по данным при создании решений для больших данных.
Hadoop
Hadoop — это надежная, распределенная и масштабируемая платформа распределенной обработки данных для хранения и анализа огромных объемов данных. Он позволяет объединять множество компьютеров в сеть, используемую для простого хранения и вычисления огромных наборов данных.
Соблазн Hadoop заключается в его способности работать на дешевом стандартном оборудовании, в то время как его конкурентам может потребоваться дорогое оборудование для выполнения той же работы. Это тоже с открытым исходным кодом. Он делает решения для больших данных доступными для повседневного бизнеса и делает большие данные доступными для тех, кто не работает в сфере высоких технологий.
Hadoop иногда используется как общий термин, относящийся ко всем инструментам в экосистеме науки о данных Apache.
MapReduce
MapRedu ceпредставляет собой модель программирования, используемую в кластере компьютеров для обработки и создания наборов больших данных с помощью параллельного распределенного алгоритма. Его можно реализовать на Hadoop и других подобных платформах.
Программа MapReduce содержит mapпроцедуру, которая фильтрует и сортирует данные в удобную для использования форму. После сопоставления данных они передаются в reduceпроцедуру, которая суммирует тенденции данных. Несколько компьютеров в системе могут выполнять этот процесс одновременно, чтобы быстро обрабатывать данные из озера необработанных данных и получать полезные результаты.
Модель программирования MapReduce имеет следующие характеристики:
- Распределенный: MapReduce — это распределенная структура, состоящая из кластеров стандартного оборудования, которое запускается mapили reduceвыполняет задачи.
- Параллельно: задачи сопоставления и сокращения всегда работают параллельно.
- Отказоустойчивый: в случае сбоя какой-либо задачи она переносится на другой узел.
- Масштабируемость: масштабирование можно произвольно. По мере того, как проблема становится больше, можно добавить больше машин для решения проблемы в разумные сроки; каркас можно масштабировать по горизонтали, а не по вертикали.
Класс Mapper в Java
Давайте посмотрим, как мы можем реализовать MapReduce в Java.
Сначала мы будем использовать класс Mapper, добавленный пакетом Hadoop ( org.apache.hadoop.mapreduce) для создания mapоперации. Этот класс сопоставляет входные пары ключ / значение с набором промежуточных пар ключ / значение. По сути, преобразователь выполняет синтаксический анализ, проекцию (выбор интересующих полей из входных данных) и фильтрацию (удаление неинтересных или искаженных записей).
Например, мы создадим картограф, который берет список автомобилей и возвращает марку автомобиля и итератор; список из Honda Pilot и Honda Civic будет возвращаться (Honda 1), (Honda 1).
public class CarMapper extends Mapper {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// We can ignore the key and only work with value
String[] words = value.toString().split(» «);
for (String word : words) {
context.write(new Text(word.toLowerCase()), new IntWritable(1));
}
}
}
История возникновения
Первое упоминание о феномене произошло в 2008 от Клаффорда Линча в статье журнала Nature. С его слов сюда можно отнести любые неоднородные знания, поступающие в размере более 150 Гб за один день.
Согласно выкладкам аналитических агентств в 2005 по всему миру оперировало более 4-5 эксабайт (4-5 млрд гигабайт). В 2010 значение выросло до 0,20 зетта-байт (1 Зб равен 1024 Эб). В это время подход «big data » рассматривался только с научно-аналитической точки зрения, но на практике не применялся. В то же время неструктурированный массив неумолимо рос. За 2 года, то есть в 2012, показатели выросли до отметки 1,8 Зб, и проблема хранения стала актуальной и произошел всплеск интереса. К началу 2015 — до 7 Зб. К развитию направления активно подключались «цифровые гиганты» — Microsoft, IBM, Oracle, EMC, а также университеты, внедряя на практике прикладные науки (инженерию, физику, социологию).

Перспективы использования Биг Дата
Blockchain и Big Data — две развивающиеся и взаимодополняющие друг друга технологии. С 2016 блокчейн часто обсуждается в СМИ. Это криптографически безопасная технология распределенных баз данных для хранения и передачи информации. Защита частной и конфиденциальной информации — актуальная и будущая проблема больших данных, которую способен решить блокчейн.
Почти каждая отрасль начала инвестировать в аналитику Big Data, но некоторые инвестируют больше, чем другие. По информации IDC, больше тратят на банковские услуги, дискретное производство, процессное производство и профессиональные услуги. По исследованиям Wikibon, выручка от продаж программ и услуг на мировом рынке в 2018 году составила $42 млрд, а в 2027 году преодолеет отметку в $100 млрд.
По оценкам Neimeth, блокчейн составит до 20% общего рынка больших данных к 2030 году, принося до $100 млрд. годового дохода. Это превосходит прибыль PayPal, Visa и Mastercard вместе взятые.
Аналитика Big Data будет важна для отслеживания транзакций и позволит компаниям, использующим блокчейн, выявлять скрытые схемы и выяснять с кем они взаимодействуют в блокчейне.
Главные цели
| Функция | Задача |
| BigData — это поток необработанных знаний | Сохранение и оперирование |
| DataMaining — структурирование данных как метод определения закономерностей | Создание единой структуры на основе обнаруженных связей для достижения единого смысла |
| Machine learning — машинное изучение, основанное на появившихся в процессе сведениях. Позднее появилось понятие Deep learning, работающее от искусственного интеллекта. | Анализирование и прогнозирование |
Используемая технология
Обрабатывание информационного поля необходимо для предоставления пользователям конкретного результата с целью эффективного применения в будущем. То есть по итогу человек должен получить максимально полезную информацию о различных предметах или явлениях, а также взвесить положительные и отрицательные моменты для выбора дальнейшего решения. Искусственный интеллект строит приблизительную модель будущего, предлагая несколько вариантов, а затем отслеживает достигнутый результат.
Существующие аналитические агентства запускают программу-симулятор для тестирования различных идей. Она предполагает и выдает готовое решение проблемы. То есть все шаги полностью автоматизированы. Таким образом, Биг Дату можно смело назвать современной альтернативой, которая пришла на смену традиционным аналитическим методам.
Источниками являются:
- интернет (социальные сети, онлайн-магазины, статьи, форумы);
- корпоративные ресурсы — деловые архивы и активные базы;
- показатели с приборов — датчики, электронные устройства, метеоданные.
При этом, несмотря на различия, происходит объединение, интеграция, направленные в дальнейшем на извлечение, получение новых знаний.
Следует помнить о главном правиле — VVV, которое служит характеристикой больших данных:
- Volume — измерение объема в физической величине, которая занимает определенное пространство на носителе. Приставка «Биг» означает получение информационного массива в размере более 150 Гб за день.
- Velocity — регулярное обновление в режиме реального времени за счет применения интеллектуальных технологий.
- Variety — абсолютная или частичная бессистемность, разнообразие.
С течением времени упомянутые выше признаки дополнили еще двумя факторами:
- Variability — способность изменяться в зависимости от внешних обстоятельств, неуправляемые всплески и спады поступающих потоков зачастую связаны с периодичностью;
- Value — изменчивость в зависимости от сложности может затруднить функционирование искусственного интеллекта. То есть сначала требуется определение степени значимости, а после этого идет этап структуризации.

Чтобы обеспечить бесперебойность функционирования системы, необходимо одновременное включение трех основополагающих факторов:
- возможность горизонтального расширения пространства, то есть увеличение количества серверов без деградации производительности;
- устойчивость к отказу, а именно — число цифровых носителей и интеллектуальных машин для предотвращения вероятности сбоя при выходе из строя одного узла должно быть увеличено;
- локальность — выделенное место для хранения и обработки информации, способствующее экономии времени, ресурсов.
Как собирают Big Data
Источниками могут быть:
- интернет — от соцсетей и СМИ до интернета вещей (IoT);
- корпоративные данные: логи, транзакции, архивы;
- другие устройства, которые собирают информацию, например, «умные колонки».
Сбор. Технологии и сам процесс сбора данных называют дата майнингом (data mining).
Сервисы, с помощью которых проводят сбор — это, например, Vertica, Tableau, Power BI, Qlik. Собранные данные могут быть в разных форматах: текст, Excel-таблицы, SAS.
В процессе сбора система находит Петабайты информации, которая после будет обработана методами интеллектуального анализа, который выявляет закономерности. К ним относят нейронные сети, алгоритмы кластеризации, алгоритмы обнаружения ассоциативных связей между событиями, деревья решений, и некоторые методы machine learning.
Кратко процесс сбора и обработки информации выглядит так:
- аналитическая программа получает задачу;
- система собирает нужную информацию, одновременно подготавливая её: удаляет нерелевантную, очищает от мусора, декодирует;
- выбирается модель или алгоритм для анализа;
- программа учится алгоритму и анализирует найденные закономерности.
Где можно найти применение
Чем больший объем известен человеку о тех или иных предметах и явлениях, тем выше вероятность проведения точного прогноза на будущее. Даже не стоит лишний раз говорить, что наибольший спрос БигДата получила в бизнесе и маркетинге. Однако это не единственное возможное применение ее на практике. BigData активно внедряется в следующих областях:
- Медицина и охрана здоровья. Увеличение размера доступных сведений о болезнях, методах лечения и применяемых препаратах позволяет побороть такие заболевания, которые в прошлом часто становились причиной летального исхода.
- Предотвращение тяжелых последствий катастроф техногенного и природного характера. Сбор идет от множества доступных датчиков с определителем точного местоположения. Такое прогнозирование способно спасти тысячи людей.
- Правоохранительные органы используют данные для определения возможного возрастания криминальной ситуации в мире с последующим принятием профилактических мер в зависимости от ситуации.
Для автоматизации бизнеса наша предлагает и оборудование, которые способны намного облегчить большинство рутинных задач, упростить рабочий процесс.
Big Data в маркетинге — пора расстаться с иллюзиями
Сколько бы поколений предсказателей не жило на Земле, сколько бы шаманов и жрецов не перепробовало все возможные инструменты предсказания, результат один, – деньги из кармана озабоченного будущем перекачивали в карман предсказателя. Сегодня вооружившись сверх мощными компьютерами, предсказатели пытаются делать тоже самое, что их достопочтенные основатели этой древнейшей профессии. Представление о человеке, как о предсказуемом и прогнозируемом автомате – ошибочно. Вот сегодня Big Data – очередной фетиш и очередной «хрустальный шар» в длинном многовековом перечне атрибутов предсказателей будущего. Все «убедительные примеры» способности к предсказанию на Big Data разваливаются или будут опровергнуты жестокой реальностью в ближайшие же годы.
Имеющие доступ к статистике: банки, телефонные компании, агрегаторы, вчера еще не знали зачем эти данные им самим нужны, а сегодня непременно хотят заработать на своих клиентах еще раз, перепродав им колонки цифр.
Методы анализа и обработки
Основы системы big data database заключаются в работе с огромным информационным полем, который постоянно дополняется сведениями с использованием следующих способов:
- глубокое анализирование с разделением на отдельные небольшие группы. Для этого применяются специализированные математические цифровые алгоритмы;
- крауд-сорсинг основан на способности принимать и направлять в переработку инфо-потоки из различных источников, число которых ограничено мощностью, но не количеством;
- сплит-тесты базируются на сравнении элементов от исходной точки до момента изменения. Это необходимо для выявления факторов, оказывающих наибольшее влияние. То есть по итогу проведения тестирования будет получен максимально точный результат;
- прогнозирование строится на внедрении новых параметров с дальнейшей проверкой поведения после поступления большого массива;
- машинное обучение с перспективой поглощения и обработки искусственным интеллектом знаний, использования их для самостоятельного обучения;
- анализирование активности в сети для разделения аудитории по интересу, месту, половозрастным признакам и другим параметрам.

Где набираться опыта самостоятельно
Python можно подтянуть на Питонтьютор, работы с базой данных — на SQL-EX. Там даются задачи, по которым на практике учатся делать запросы.
Высшая математика — Mathprofi. Там можно получить понятную информацию по математическому анализу, статистике и линейной алгебре. А если плохо со школьной программой, то есть сайт youclever.org
Распределенные же вычисления тренировать получится только на практике. Во-первых для этого нужна инфраструктура, во-вторых алгоритмы могут быстро устаревать. Сейчас постоянно появляется что-то новое.
Разрабатываемые решения
Биг дейта — это возможность эффективного использования полученных сведений в удобной и наглядной форме для выполнения прикладных задач. Основным источником является человек, при этом могут быть использованы самые различные средства (соцсети, СМИ и др.). Данные используются в первую очередь для проведения анализа с последующим созданием продуктов. Это могут быть консультации, товары или услуги, возможно внедрение программ оптимизации потребления ресурсов, прогнозирование. При этом важно защитить серверы от мошеннических манипуляций и угрозы вируса. Учитывая характер полученных сведений, программист сможет создать уникальные платформы и барьеры, защищающие от утечки.
Продуктивная реклама: 3 простых способа оптимизации рекламного бюджета
Чтобы реклама стала двигателем торговли, она должна быть эффективной, т.е. обеспечивать высокую конверсию. Этот показатель описывает отношение целевого результата к затратам на его достижение. Например, сколько процентов посетителей сайта оставили заявку на товар/услугу, какова доля полученной выручки с продаж от потраченного рекламного бюджета и т.д. При этом эффективность рекламного бюджета зависит не столько от инвестиций в него, сколько от точности соответствия рекламных предложений потребностям потенциальных покупателей [1].
А поскольку рекламные бюджеты всегда ограничены, работа маркетолога сводится к увеличению отклика (заявок, продаж и прочих целевых действий) в условиях минимизации затрат на привлечение покупателей. Это возможно за счет следующих вариантов:
- специальное таргетирование – реклама показывается только той целевой аудитории (ЦА), которая действительно заинтересована в товаре/услуге. Например, гостиничные предложения для тех, кто ищет билеты на самолет или поезд в другой город.
- персонализация рекламного предложения – индивидуальное звучание ключевой фразы для узкого сегмента ЦА. К примеру, luxury-отели для премиум-клиентов и бюджетные хостелы для тех, кто хочет сэкономить.
- выбор оптимального рекламного канала – контекстная реклама в поисковых системах, социальных сетях, звучные/зрелищные ролики по радио или телевидению, красочные плакаты на биллбордах вдоль автомагистралей или раздача бумажных промоматериалов на улице. Не нужно пытаться охватить все каналы доставки информации потенциальному клиенту, достаточно сосредоточиться на тех, которые приносят максимальный трафик. Сегодня практически для всех отраслей экономики таким каналом становится интернет: контекстная реклама, соцсети и поисковое продвижение через полезный контент на сайте.
Таким образом, оптимизация рекламного бюджета сводится к отказу от непродуктивных каналов и нецелевых показов. Эти меры позволят наладить стабильную лидогенерацию, т.е. привлечь новых посетителей и превратить их в покупателей.
Отказ от непродуктивных каналов и нецелевых показов – шаг к оптимизации рекламного бюджета
Как происходило развитие в мире
Рост объема получаемой информации ежегодно растет в геометрической прогрессии. Если в 2003 году он составлял всего 5 Эб, то в 2015 этот показатель возрос до 6,5 Зб и до сих пор продолжает увеличиваться. При этом новые полученные знания можно смело назвать жизненно важным активом, а основы безопасности должны стать фундаментом. Повсеместное возрастание значимости феномена способно кардинально изменить экономическую ситуацию в мире, а незаинтересованный пользователь будет находиться в постоянном контакте с различными электроустройствами.
Хотите примеры?
Конечно же любое мнение можно опровергнуть. Если не сейчас, то лет через триста, когда и опыт появится и технологии пойдут дальше. Но сегодня есть примеры, подтверждающие сомнения о возможности прогнозирования на Big Data. Примеры эти довольно убедительны.
Как прогнозировали грипп?
Самым любимым у многих адептов предсказаний на «биг дата» был Google Flu Trends — графики убедительно показывали, что можно предсказывать эпидемии гриппа в интернете, быстрее и надежнее, чем врачи. Достаточно проанализировать запросы пользователей о названии лекарств, их описаний и адресов аптек. Этот пример кочевал из презентации в презентации, из статьи в статью. В результате попал и в серьезные книжки. Раз сработало, а дальше? Все оказалось не точнее, чем у отечественного Гидрометцентра. Первый сигнал об ошибке был в 2009 году, когда он совершенно пропустил мировую эпидемию «свиного» гриппа. В 2012 система вновь дала сбой — Google Flu Trends более чем в два раза переоценил пик очередной эпидемии. (Пишет журнал Nature.)
Прогноз победы
Во время выборов в Конгресс на праймерез в Виргини, по мнению аналитиков, на выборах должен был победить Э. Кантор из Республиканской партии. И действительно, он шел с отрывом в 34% от конкурентов. Однако, сокрушительно проиграл — минус 10% от победившего. Ошибка была в том, что модель ориентировалась на «типичных избирателей», учитывала их историю голосований, поведение и предпочтения. Но в этот раз явка оказалась сильно выше, чем обычно, в игру включились избиратели, которые не вписывались в модель. Но пример победы на выборах президента Трампа и однозначные прогнозы всех аналитиков не в его пользу – это куда более убедительный пример того, что прогнозы на Big Data – дело стрёмное!
Пишите длинные тексты
… учили еще несколько лет назад те, кто наблюдал за алгоритмом ранжирования поисковой системы Google. Две тысячи знаков, цифры и буллиты, ссылки на первоисточники – это то немногое, что сулило успех в ранжировании сайта. В ходе практической реализации этого совета, SEO-специалисты начали повально писать сложные и длинные тексты, даже на главную страницу сайта – если ты знаешь алгоритм, то всегда можешь повлиять на результаты. Если вы знаете алгоритм работы прогноза на основе Big Data вы легко можете обмануть систему.
Ворота МТС
Еще в 2015 году на Форуме «Future of Telecom» руководитель направления Big Data Виталий Сагинов рассказывал о подходах компании в развитии направления по работе с «большими данными». В своем докладе он о. Замечательно, но в мае 2022 года все новостные ленты и ТВ облетела информация о том, что житель Москвы Алексей Надежин клиент этого сотового оператора связи обнаружил, что его ворота, установленные, на въезде в садоводческое товарищество «самостоятельно» подписались на платные SMS-сервисы отвечали на посылаемую им информацию.
В пресс-службе МТС тогда рассказали, что «специалисты провели необходимые работы, чтобы подобный случай не повторился». Означает ли это, что ворота сами что-то набирали в телефоне или подписки были оформлены без согласия абонента, в комментарии компании не уточняется. Вот только на симку, установленную в автоматике ворот приходило множество СМС с коротких номеров, а ворота, оказывается, «сами» им отвечали, отправляя СМС в ответ. Ну и где же результат многолетней работы с «большими данными» для недопущения подобного? Заявлять о умении собирать, анализировать и прогнозировать на Big Data – это еще не означает делать это с адекватным качеством!
А что Procter&Gamble?
На крупнейшей европейской выставки и конференции по вопросам цифрового маркетинга Dmexco’2017, прошедшей в Кельне, Procter&Gamble в своей презентации подробно остановился на том, что компания сильно сократила бюджеты, выделяемые на программатические закупки. Крупнейший транснациональный рекламодатель такого уровня впервые открыто, на публике спорил с тезисом рекламно-технологических компаний (англ. AdTech), до сих пор утверждавших, что охват пользователей гораздо важнее источника прямого рекламного трафика. В результате компания радикально сократила список интернет-площадок на которых готова размещать свою рекламу – нет адекватной прогнозной модели, незачем тратить деньги на формирование чего-либо в будущем.
Как Сбербанк от искусственного интеллекта пострадал
В феврале 2022 года во время своего выступления на «Уроке цифры» в частной школе в Москве глава Сбербанка Герман Греф, отвечая на вопрос о рисках внедрения технологий, сказал: «Искусственный интеллект, как правило, принимает решение в больших системах. Маленькая ошибка, закравшаяся в алгоритм, может приводить к очень большим последствиям». Отвечая на запрос РБК о сути потерь от внедрения искусственного интеллекта, в пресс-службе Сбербанка уточнили, что «речь идет не о прямых убытках, а скорее о недополученной прибыли». Тем не менее, глава банка высказался о потерях определенно, смысл его заявления в том, что Сбербанк в результате ошибок искусственного интеллекта уже потерял миллиарды рублей.

Готовые решения для всех направлений
Магазины
Мобильность, точность и скорость пересчёта товара в торговом зале и на складе, позволят вам не потерять дни продаж во время проведения инвентаризации и при приёмке товара.
Узнать больше
Склады
Ускорь работу сотрудников склада при помощи мобильной автоматизации. Навсегда устраните ошибки при приёмке, отгрузке, инвентаризации и перемещении товара.
Узнать больше
Маркировка
Обязательная маркировка товаров — это возможность для каждой организации на 100% исключить приёмку на свой склад контрафактного товара и отследить цепочку поставок от производителя.
Узнать больше
E-commerce
Скорость, точность приёмки и отгрузки товаров на складе — краеугольный камень в E-commerce бизнесе. Начни использовать современные, более эффективные мобильные инструменты.
Узнать больше
Учреждения
Повысь точность учета имущества организации, уровень контроля сохранности и перемещения каждой единицы. Мобильный учет снизит вероятность краж и естественных потерь.
Узнать больше
Производство
Повысь эффективность деятельности производственного предприятия за счет внедрения мобильной автоматизации для учёта товарно-материальных ценностей.
Узнать больше
RFID
Первое в России готовое решение для учёта товара по RFID-меткам на каждом из этапов цепочки поставок.
Узнать больше
ЕГАИС
Исключи ошибки сопоставления и считывания акцизных марок алкогольной продукции при помощи мобильных инструментов учёта.
Узнать больше
Сертификация для партнеров
Получение сертифицированного статуса партнёра «Клеверенс» позволит вашей компании выйти на новый уровень решения задач на предприятиях ваших клиентов..
Узнать больше
Инвентаризация
Используй современные мобильные инструменты для проведения инвентаризации товара. Повысь скорость и точность бизнес-процесса.
Узнать больше
Мобильная автоматизация
Используй современные мобильные инструменты в учете товара и основных средств на вашем предприятии. Полностью откажитесь от учета «на бумаге».
Узнать больше Показать все решения по автоматизации
Повышение лояльности клиентов
32% руководителей компаний отдают приоритет удержанию клиентов. Это не удивительно, ведь привлечение новых обходится в 5-25 раз дороже, чем сохранение существующих.
При повышении клиентской лояльности нужны данные. И чем больше, тем лучше. Анализируйте продажи, и вы поймете, какие товары еще можно предложить. К примеру, у вас есть три похожих продукта в ассортименте, и клиент покупал два из них. Высока вероятность, что он будет чувствителен к рекламе третьего продукта.
В дополнение к персонализированному Email-маркетингу, загрузите узкий сегмент своих клиентов в Facebook или VK. Потом запустите в социальной сети рекламу на эту аудиторию и продвигайте свой продукт. Эти люди уже знают ваш бренд, а значит конверсия будет выше, чем при привлечении новых клиентов.
Настройте триггеры так, чтобы клиенты получали автоматические письма в определенные события, в день рождения или при отправке заказа.
Не считайте целью удержания – вытащить как можно больше денег из клиента.
Дарите потрясающий клиентский опыт, отправляйте персональный контент и индивидуальные предложения. Это даст больше выгод в долгосрочной перспективе. Это прибыльнее.
Ситуация в России
На территории РФ услуги и технологии системы BigData находятся на начальном этапе развития, если сравнивать текущую мировую ситуацию. Наибольшее распространение она получила в банковской, энергетической, логистической сфере, промышленности, электросвязи, на уровне защиты государства. Рынок также находятся на стадии зарождения. На сегодняшний день внутри страны в качестве поставщика могут выступать разработчики платформ управления (DMP) и владельцы банков данных (data exchange). Представители телефонии запустили обмен знаниями лишь в пилотном режиме.
Снижение коэффициента оттока клиентов
Используйте предиктивный анализ для уменьшения коэффициента оттока. Составьте список клиентов, которые имеют высокую вероятность ухода. Одним из факторов оттока может быть период неактивности в личном кабинете.
Теперь разработайте и запустите кампанию для возврата. Это может быть предложение специальных бонусов, которые покажут клиенту, что вы им дорожите.

Использование в банках
Учитывая, что банковская сфера относится к группе повышенной опасности, то внедрение анализа супермассива просто необходимо. Он защитит от мошенничества, поможет управлять рисками, оптимизирует расходы и позволит улучшить качество обслуживания. Все эти факторы в значительной степени влияют на лояльность потенциального клиента, а значит прибыль будет только возрастать. Эффективность работы системы уже успели оценить современные гиганты банковского дела: Сбербанк, ВТБ24, Альфа-Банк, Тинькофф.
Имитационное моделирование
Отличие имитационного моделирования от предиктивной аналитики в том, что прогнозы делаются не на реальных, а на теоретически возможных или желаемых данных. Построение моделей происходит с использованием методов Big Data, при помощи которых эксперимент проводят, если можно так выразиться, в виртуальной реальности.
Метод подходит для анализа воздействия различных факторов на конечный результат. Для оценки уровня продаж изучают воздействие цены, количества клиентов, количестве продавцов, наличие скидок или предложений для постоянных клиентов и пр. Изменение показателей влияет на другие, после чего можно определить удачный для внедрения вариант. Для имитационного моделирования лучше использовать большое количество факторов, чтобы снизить риски при создании модели.
Интеграция в бизнесе
Пользователей можно условно отнести к 5 группам, осуществляющим различную деятельность:
- поставщики, в задачи которых входит решение вопроса хранения и проведения предварительной обработки инфо-продукта;
- датамайнеры, занимающиеся созданием уникальных алгоритмов, нацеленных на извлечение узкоспециализированных знаний;
- системная интеграция, осуществляющая сбор и передачу данных от клиента;
- потребители, приобретающие новые программы;
- создатели сервисов, предлагающие доступ к БигДата расширенному числу пользователей.

В 2012 году на рынок запущен Big Query — облако для анализирования Большой информации в режиме настоящего времени. В следующем году в него внедрили PremiumAnalytics — анализатор-счетчик для корпоративных клиентов на платной основе. Недавно в свет вышла Cloud Bigtable — горизонтально увеличивающийся облачный сервис для хранения.
«Яндекс»
Компания выстроила на основе системы практически всю работу: алгоритм поиска, автоматический переводчик, защиту от спама, таргет-рекламу, анализ и прогноз пробок, определение речи и лица.
До недавнего времени, для консультации крупным компаниям необходимо было обращаться в Yandex Data Factory, однако на сегодняшний день она полностью перенесена в поисковый отдел.
Mail.Ru Group
Группа одна из первых начала применение уникальной технологии на практике. При этом они внедрены во все сервисы. Благодаря внедрению новой методики, MailRu готов предложить таргетирование рекламы, оптимизацию поисковых запросов, быструю работу группы техподдержки, фильтрацию и защиту от нежелательных писем.
«Рамблер»
Первое время феномен нашел применение только в поисковых запросах, но немного позднее начало развиваться направление дата-майнинга. В работе применяется методика разделения контента, блокирование нежелательных ресурсов, обработка.

Какие выгоды достигнуты
Каждое новое изобретение должно нести в себе существенную пользу, чтобы его оценили по достоинству. Такой критерий применим и для БигДаты:
- более простое планирование;
- быстрый запуск инфо-продуктов;
- востребованность продукта;
- возможность оценки удовлетворенности от использования;
- облегченный поиск ключевой аудитории;
- оптимизация поставок;
- улучшение качества и увеличение скорости взаимодействия;
- повышение лояльности заказчика.
Где можно получить образование по Big Data (анализу больших данных)?
GeekUniversity совместно с Mail.ru Group открыли первый в России факультет Аналитики Big Data.
Для учебы достаточно школьных знаний. У вас будут все необходимые ресурсы и инструменты + целая программа по высшей математике. Не абстрактная, как в обычных вузах, а построенная на практике. Обучение познакомит вас с технологиями машинного обучения и нейронными сетями, научит решать настоящие бизнес-задачи.

После учебы вы сможете работать по специальностям:
- Big Data (анализ больших данных).
- Искусственный интеллект,
- Машинное обучение,
- Нейронные сети.
Особенности изучения Big Data в GeekUniversity
Через полтора года практического обучения вы освоите современные технологии Data Science и приобретете компетенции, необходимые для работы в крупной IT-компании. Получите диплом о профессиональной переподготовке и сертификат.
Обучение проводится на основании государственной лицензии № 040485. По результатам успешного завершения обучения выдаем выпускникам диплом о профессиональной переподготовке и электронный сертификат на портале GeekBrains и Mail.ru Group.
Проектно-ориентированное обучение
Обучение происходит на практике, программы разрабатываются совместно со специалистами из компаний-лидеров рынка. Вы решите четыре проектные задачи по работе с данными и примените полученные навыки на практике. Полтора года обучения в GeekUniversity = полтора года реального опыта работы с большими данными для вашего резюме.
Наставник
В течение всего обучения у вас будет личный помощник-куратор. С ним вы сможете быстро разобраться со всеми проблемами, на которые в ином случае ушли бы недели. Работа с наставником удваивает скорость и качество обучения.
Основательная математическая подготовка
Профессионализм в Data Science — это на 50% умение строить математические модели и еще на 50% — работать с данными. GeekUniversity прокачает ваши знания в матанализе, которые обязательно проверят на собеседовании в любой серьезной компании.
Применение в маркетинге
Система стала одним из наиболее востребованных инструментов маркетологов, который способен спрогнозировать результат. При этом появляется возможность привлечения клиентов, повышения лояльности и оценки их удовлетворенности.
Извлечение выгоды
Повсеместное внедрение БигДаты в маркетинг объясняется следующими факторами:
- возможность нарисовать портрет потребителя;
- предугадывание реакции;
- написание персональной рекламы;
- повышение продаж;
- доработка продукта или услуги с целью увеличить лояльность потенциального клиента;
- защита от мошенников.
Статистический анализ
Метод предполагает сбор материалов, а также расчет по заданным критериям для получения результата. Недостаток статистики в том, что в выборку могут попасть недостоверные результаты из маленького опроса, поэтому для более достоверных результатов необходимо увеличить количество исходной информации для обработки.
Статистические данные используют в машинном обучении для получения комплексного прогноза по базовой модели, в предиктивной аналитике и имитационном моделировании.

К статистике относят анализ временных рядов и А/В тестирование. A/B testing или split testing – это маркетинговый метод исследования, при котором сравнивают контрольную группу элементов с наборами тестовых групп с измененными параметрами, чтобы определить, какие факторы улучшают целевые показатели.
Методы для получения статистических результатов:
- Корреляционный анализ для выявления взаимосвязей и того, как изменение одних показателей влияет на другие.
- Подсчет процентного соотношения результатов исследования.
- Динамические ряды для оценивания частоты и интенсивности изменений условий на протяжении времени.
- Вычисление среднего показателя.
Перспективы развития
Понимание важности внедрения феномена big data technologies возрастает с каждым днем. Именно поэтому происходит повсеместная его интеграция в самые разные сферы деятельности человека:
- облако-хранилище гораздо проще и дешевле, а IT-персоналу доступна удаленная работа;
- возможность сбора и хранения второстепенной информации о компаниях, которая не играет существенной роли, но при этом обязательна со стороны законодательства;
- разработка Blockchain для более простого проведения транзакций с последующим снижением затрат;
- создание искусственного интеллекта и внедрение глубокого обучения позволяют перенести всю ответственность на машины, при это все происходит четче и быстрее;
- системы самостоятельного обслуживания и систематизации.

Визуализация аналитических данных
Для упрощения процесса анализа информации используют метод визуализации данных. Выполнить визуализацию Big Data можно при помощи средств виртуальной реальности и «больших экранов». Визуальные образы воспринимаются лучше текста, поскольку 90% информации человек получает через зрение.
При помощи визуализации аналитических данных можно оперативно оценить колебания продаж в разных регионах на гистограмме или карте, обозначив регионы отличающимися цветами, либо на графике показать зависимость уровня продаж от изменения стоимости продукции.
Результаты выводят в виде диаграмм, карт, графиков, гистограмм, 3-D моделей, либо пиктограмм. Инструменты для визуализации больших данных: Qlik, Microsoft (Excel, Power BI), Tableau (tableau desktop, tableau public), Orange и Microstrategy.
Сервисы
На сегодняшний день выделяют 4 основополагающих направления.
«1С-Битрикс BigData: что это»
Облако для персонализации коммерческих услуг, который интегрируется в алгоритм управления сайтом. При этом достигается лучший результат от рекламы. Как следствие, увеличивается средняя стоимость, растет спрос, формируются персональные предложения.
RTB-Media
Портал управления продаж рекламы в цифровом формате с функцией участия в аукционах. Подходит для настройки кросс-канала, поискового и товарного таргетирования.
Alytics
Анализ-система с функцией автоматической разработки рекламы и подготовки отчета. С ней получится правильно оперировать рекламным бюджетом, используя различные показатели.
Crossss
Платформа для многоканальной персонализации онлайн-магазина. Производит сбор запросов пользователей с последующим анализом для разработки персональной рекламной акции. Продукция в каталоге выстраивается по специальному алгоритму, подходящему только для одного человека.
Достигнутые на сегодняшний день результаты в области цифровых технологий не конечные. Развиваясь и дальше, человек пополняет свои знания, которые обязательно должны сохраниться и использоваться. Система работы с большими объемами данных (big data) постоянно совершенствуется, раскрывая новые возможности.
Количество показов: 10868
Инструменты создания
Конечно же огромные объемы информации не могут храниться и обрабатываться на простых жестких дисках.
А программное обеспечение, которое структурирует и анализирует данные – это вообще интеллектуальная собственность и каждый раз авторская разработка. Однако, есть инструменты, на основе которых создается вся эта прелесть:
- Hadoop & MapReduce;
- NoSQL базы данных;
- Инструменты класса Data Discovery.
Если честно, я не смогу Вам внятно объяснить, чем они отличаются друг от друга, так как знакомству и работе с этими вещами учат в физико-математических институтах.
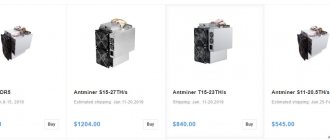
Зачем тогда я об этом заговорил, если не смогу объяснить? Помните, во всех кино грабители заходят в любой банк и видят огромное число всяких железяк, подключенных к проводам? То же самое и в биг дате. К примеру, вот модель, которая является на данный момент одним из лидеров на рынке.

Инструмент Биг дата
Стоимость в максимальной комплектации доходит до 27 миллионов рублей за стойку. Это, конечно, люксовая версия. Я это к тому, чтобы Вы заранее примерили создание big data в своем бизнесе.