Немного истории
В 1957 году Фрэнк Розенблатт изобрёл вычислительную систему «Марк-1», которая стала первой реализацией перцептрона. Этот алгоритм тоже использует интерпретацию линейного классификатора и функцию потерь, но на выходе выдаёт либо 0, либо 1, без промежуточных значений.

Индикаторы и переключатели «Марк I»
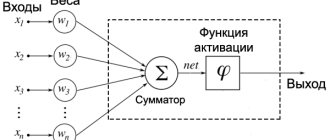
На вход перцептрона подаются веса w и исходные данные x, а их произведение корректируется смещением b.
В 1960 году Бернард Уидроу и Тед Хофф разработали однослойную нейросеть ADALINE и её улучшенную версию — трёхслойную MADALINE. Это были первые глубокие (для того времени) архитектуры, но в них ещё не использовался метод обратного распространения ошибки.

ADALINE
Алгоритм backpropagation появился в 1986 году в работе Дэвида Румельхарта, которая называлась «Многослойный перцептрон». В нём используются уже знакомые нам уравнения, правило дифференцирования и выходные значения в диапазоне от 0 до 1.
Затем в развитии машинного обучения начался период застоя, поскольку компьютеры того времени были не пригодны для создания масштабных моделей. В 2006 году Джеффри Хинтон и Руслан Салахутдинов опубликовали статью, в которой показали, как можно эффективно обучать глубокие нейросети. Но даже тогда они пока не приобрели современный вид.
Первых по-настоящему впечатляющих результатов исследователи искусственного интеллекта достигли в 2012 году, когда почти одновременно появились успешные решения задач распознавания речи и классификации изображений. Тогда же была представлена первая свёрточная нейросеть AlexNet, которая достигла высокой на тот момент точности классификации датасета ImageNet. С тех пор подобные архитектуры довольно широко применяются в разных областях.
Обзор
При применении для распознавания изображений сверточные нейронные сети (СНС) состоят из нескольких слоев небольших сборников нейронов, которые обрабатывают части входного изображения, называемые рецептивными полями .Выходы этих сборников затем укладываются таким образом, чтобы они перекрывались, для получения лучшего представления первичного изображения это повторяется для каждого такого слоя. Заключение с перекрытием позволяет СНСбыть терпимыми к параллельных переносов входного изображения. [6]
Сверточные сети могут включать слои локальной или глобальной подвыборки, которые сочетают выходы кластеров нейронов.[7] [8] Они также состоят из различных комбинаций згорткових и полносвязных слоев, с применением поточечной нелинейности [en] в конце каждого слоя. [9] для снижения числа свободных параметров и улучшения обобщения вводится операция свертки на малых областях входа. Одним из главных преимуществ згорткових сетей является использование совместной веса в згорткових слоях, что означает, что для каждого пикселя слоя используется один и тот же фильтр (банк веса) это как уменьшает объем требуемой памяти, так и улучшает производительность. [3]
Очень подобную згорткових нейронных сетей архитектуру также применяют и некоторые нейронные сети с временной задержкой [en] , особенно предназначенные для задач распознавания и / или классификации изображений, поскольку заключения выходов нейронов может быть осуществлено через определенные промежутки времени, удобным для анализа изображений образом. [ 10]
По сравнению с другими алгоритмами классификации изображений, сверточные нейронные сети используют относительно мало предварительной обработки. Это означает, что сеть несет ответственность за обучение фильтров, в традиционных алгоритмах разрабатывались вручную . Отсутствие зависимости в разработке признаков от априорных знаний и человеческих усилий является большим преимуществом ОНР.
Нейросети повсюду
Свёрточные сети хорошо справляются с огромными наборами данных и эффективно обучаются на графических процессорах за счёт параллельных вычислений. Эти особенности стали ключом к тому, что в настоящее время искусственный интеллект используется практически везде. Он решает задачи классификации и поиска изображений, обнаружения объектов, сегментации, а также применяется в более специализированных областях науки и техники.

Примеры задач классификации и поиска изображений

Примеры детектирования объектов и сегментации
Нейросети активно развиваются и уже используются в автономных автомобилях, в задачах распознавания лиц, классификации видео, определения позы или жестов человека. Кстати, именно свёрточные архитектуры научились обыгрывать людей в шахматы и . Среди других специфичных применений — анализ медицинских изображений, сегментация географических карт, составление текстового описания по фото (Image captioning) и перенос стиля художников на фотографии.

Примеры переноса стиля
Эта лишь малая часть примеров использования свёрточных сетей. Давайте разберёмся, как они работают и что делает их такими разносторонними.
Обучение и оценка модели
Как только модель нейронной сети определена, мы готовы обучать модель, то есть настраивать параметры всех сверточных слоев. Отсюда, чтобы узнать, насколько хорошо работает наша модель, мы должны сделать то же самое, что и в примере с Keras в предыдущем посте «Глубокое обучение для начинающих: практическое руководство по Python и Keras». По этой причине и во избежание повторений мы будем использовать код, уже представленный выше:
from keras.datasets import mnistfrom keras.utils import to_categorical(train_images, train_labels), (test_images, test_labels) = mnist.load_data()train_images = train_images.reshape((60000, 28, 28, 1))train_images = train_images.astype(‘float32’) / 255test_images = test_images.reshape((10000, 28, 28, 1))test_images = test_images.astype(‘float32’) / 255train_labels = to_categorical(train_labels)test_labels = to_categorical(test_labels)model.compile(loss=’categorical_crossentropy’, optimizer=’sgd’, metrics=[‘accuracy’])model.fit(train_images, train_labels, batch_size=100, epochs=5, verbose=1)test_loss, test_acc = model.evaluate(test_images, test_labels)print(‘Test accuracy:’, test_acc)Test accuracy: 0.9704
Как и в предыдущих случаях, код можно найти в GitHub (исходный код на GitHub)книги, и можно убедиться, что этот код обеспечивает точность около 97%.
Если читатель выполнил код на компьютере только с процессором, будет замечено, что на этот раз обучение сети заняло намного больше времени, чем в предыдущем примере, даже всего с 5 эпохами. Можете ли вы представить, сколько времени может занять сеть из множества слоев, эпох или изображений? Отсюда, как мы уже обсуждали во введении к книге, нам необходимо обучить нейронные сети для реальных случаев с большим количеством вычислительных ресурсов, таких как графические процессоры.
Как устроены свёрточные сети
На прошлой лекции мы обсудили идею создания полносвязных линейных слоёв. Предположим, что у нас есть исходное 3D-изображение 32x32x3. Растянем его в один длинный вектор 3072×1 и перемножим с матрицей весов размером, для примера, 10×3072. В итоге нам нужно получить активацию (вывод с оценками классов) — для этого берём каждую из 10 строк матрицы и выполняем скалярное произведение с исходным вектором.
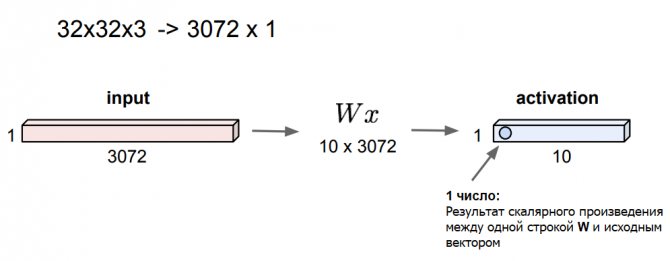
В результате получим число, которое можно сравнить со значением нейрона. В нашем случае получится 10 значений. По этому принципу работают полносвязные слои.
Основное отличие свёрточных слоёв в том, что они сохраняют пространственную структуру изображения. Теперь мы будем использовать веса в виде небольших фильтров — пространственных матриц, которые проходят по всему изображению и выполняют скалярное произведение на каждом его участке. При этом размерность фильтра (не путать с размером) всегда соответствует размерности исходного снимка.
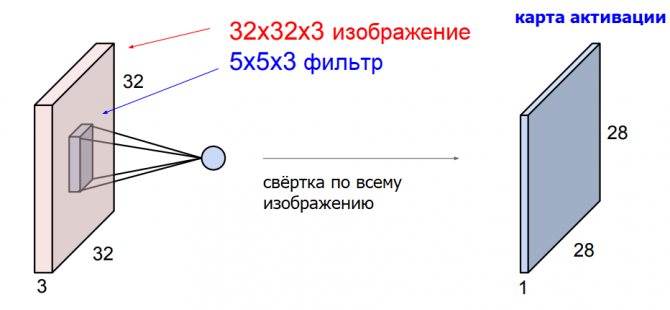
В результате прохода по изображению мы получаем карту активации, также известную как карта признаков. Этот процесс называется пространственной свёрткой — более подробно о нём можно почитать в статье Свёртка в Deep Learning простыми словами. Из неё вы также можете узнать, почему размер карты активации получается меньше, чем у исходной фотографии.
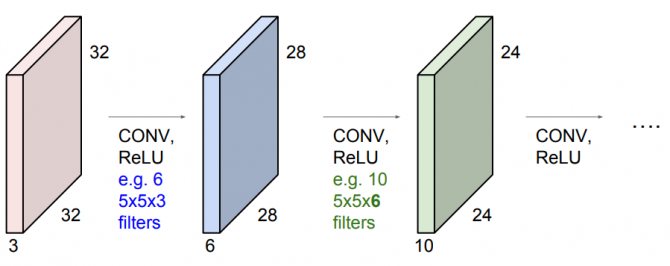
К изображению можно применять множество фильтров и получать на выходе разные карты активации. Так мы сформируем один свёрточный слой. Чтобы создать целую нейросеть, слои чередуются друг за другом, а между ними добавляются функции активации (например, ReLU) и специальные pooling-слои, уменьшающие размер карт признаков.
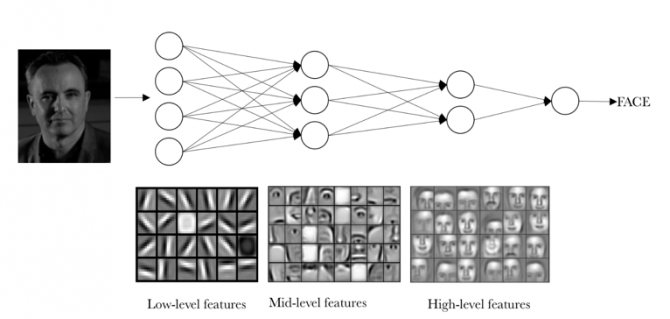
Рассмотрим подробнее, что же представляют собой свёрточные фильтры. В самых первых слоях они обычно соотносятся с низкоуровневыми признаками изображения, например, с краями и границами. В середине присутствуют более сложные особенности, такие как углы и окружности. И в финальных слоях фильтры уже больше напоминают некие специфичные признаки, которые можно интерпретировать более широко.
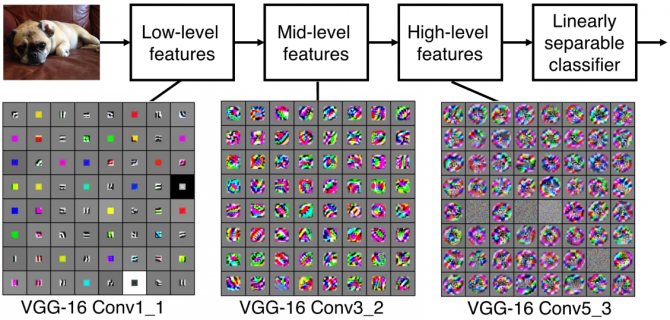
Примеры фильтров для свёрточных слоёв нейросети VGG-16
На рисунке ниже показаны примеры фильтров 5×5 и карты активации, которые получаются в результате их применения к исходному изображению (в левом верхнем углу). Первый фильтр (обведён в красную рамку) похож на небольшой участок границы, наклонённой вправо. Если мы применим его к фотографии, то наиболее высокие значения (белого цвета) получатся в тех местах, где есть края примерно с такой же ориентацией. В этом можно убедиться, посмотрев на первую карту активации.

Таким образом, один слой нейросети находит наиболее похожие на заданные фильтры участки изображения. Этот процесс очень похож на обычную свёртку двух функций. Она показывает, насколько объекты коррелируют друг с другом.
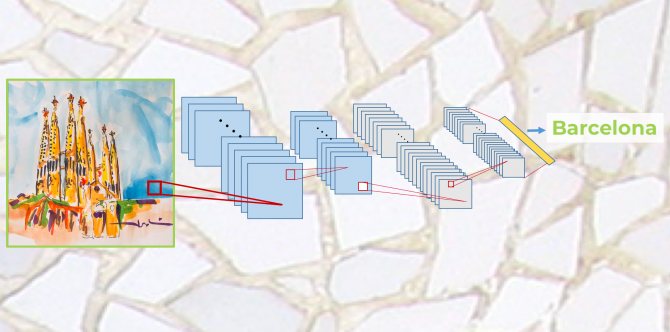
Сложив всё вместе, мы получим примерно следующую картину: взяв исходную фотографию, мы проводим её через чередующиеся свёрточные слои, функции активации и pooling-слои. В самом конце мы используем обычный полносвязный слой, соединённый со всеми выводами, который показывает нам итоговые оценки для каждого класса.
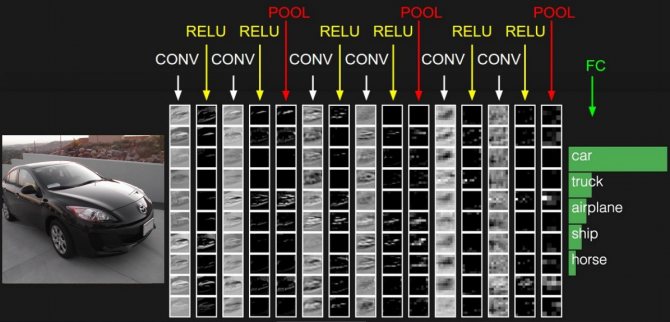
Схема работы свёрточной нейросети
По такому принципу работают современные свёрточные нейросети.
Какой бывает пулинг
Способов уменьшить размерность пространства карт особенностей на самом деле может быть весьма много: можно выбирать максимальные значения (макспулинг), можно усреднять значения (средний пулинг), брать сумму (пулинг суммы) или вовсе взять минимум. Чаще всего в свёрточных сетях в слое подвыборки используется макспулинг, как хорошо зарекомендовавший себя в многочисленных исследованиях. Чтобы лучше понимать, как влияет на выходное изображение различные типы пулинга, мы предлагаем самостоятельно выбрать тип подвыборки в интерактивном примере ниже:
Если же пример с изображением кажется слишком неочевидным, то, надеемся, расположенная ниже гифка поможет разобраться с работой слоя подвыборки:
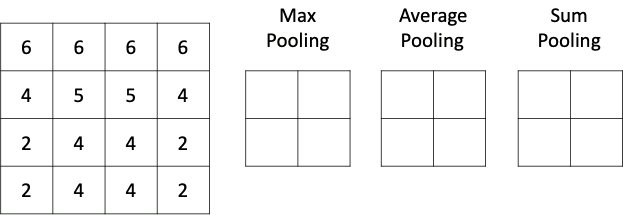
Различные типы пулинга
Полносвязный слой
Данный слой содержит матрицу весовых коэффициентов и вектор смещений и ничем не отличается от такого же слоя в обыкновенной полносвязной сети. Единственным гиперпараметром слоя является количество выходных значений. При этом результатом применения слоя является вектор или тензор, у которого матрицы в каждом канале имеют размер 1х1. Подробнее о работе слоя можно посмотреть в статье про создание нейронной сети прямого распространения.
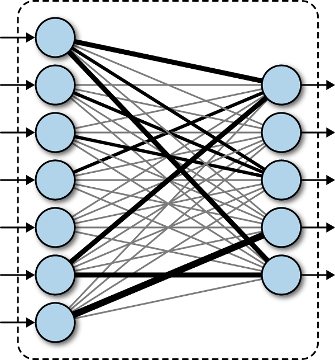
Полносвязный слой
Слой активации
Данный слой представляет из себя некоторую функцию, которая применяется к каждому числу входного изображения. Наиболее часто используются такие функции активации, как ReLU, Sigmoid, Tanh, LeakyReLU. Обычно активационный слой ставится сразу после слоя свёртки, из-за чего некоторые библиотеки даже встраивают ReLU функцию прямо в свёрточный слой. Подробнее про функции активации можно почитать здесь: функции активации.
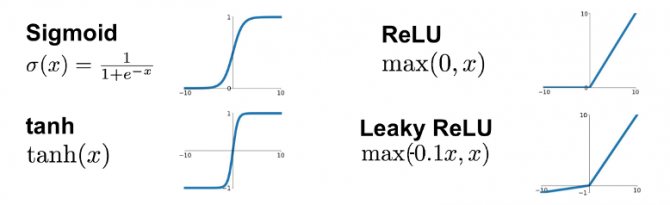
Функции активации
Fast R-CNN
Несмотря на высокие результаты, производительность R-CNN была всё же невысока, особенно для более глубоких, чем CaffeNet сетей (таких как VGG16). Кроме того, обучение bounding box regressor и SVM требовало сохранения на диск большого количества признаков, поэтому оно было дорогим с точки зрения размера хранилища.
Авторы Fast R-CNN предложили ускорить процесс за счёт пары модификаций:
- Пропускать через CNN не каждый из 2000 регионов-кандидатов по отдельности, а всё изображение целиком. Предложенные регионы потом накладываются на полученную общую карту признаков;
- Вместо независимого обучения трёх моделей (CNN, SVM, bbox regressor) совместить все процедуры тренировки в одну.
Преобразование признаков, попавших в разные регионы, к фиксированному размеру производилось при помощи процедуры RoIPooling. Окно региона шириной w и высотой h делилось на сетку, имеющую H×W ячеек размером h/H × w/W. (Авторы документа использовали W=H=7). По каждой такой ячейке проводился Max Pooling для выбора только одного значения, давая таким образом результирующую матрицу признаков H×W. Бинарные SVM не использовались, вместо этого выбранные признаки передавались на полносвязанный слой, а затем на два параллельных слоя: softmax с K+1 выходами (по одному на каждый класс + 1 для фона) и bounding box regressor.
Общая архитектура сети выглядит так:
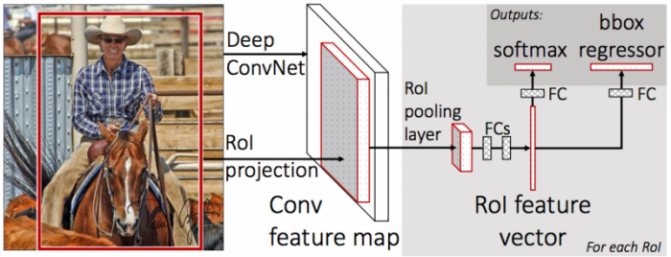
Для совместного обучения softmax-классификатора и bbox regressor-а использовалась объединённая loss-функция:
L(p,u,tu,v)=Lcls(p,u)+λ[u≥1]Lloc(tu,v)
Здесь: u — класс объекта, реально изображённого в регионе-кандидате;
Lcls(p,u)=−log(pu) – log loss для класса u;
v=(vx,vy,vw,vh) – реальные изменения рамки региона для более точного охватывания объекта; tu=(txu,tyu,twu,thu) – предсказанные изменения рамки региона; Lloc – loss-функция между предсказанными и реальными изменениями рамки; [u≥1] – индикаторная функция, равная 1, когда u≥1, и 0, когда наоборот. Классом u=0 обозначается фон (т.е. отсутствие объектов в регионе).
λ – коэффициент, предназначенный для балансирования вклада обоих loss-функций в общий результат. Во всех экспериментах авторов документа, он, однако, был равен 1.
Авторы так же упоминают, что для ускорения вычислений в полносвязанном слое они использовали разложение матрицы весов по Truncated SVD.